
Unmasking the Threat: A Deep Dive into the PDF Malicious

Analyzing the Sophisticated Use of PDF Files as Cyberattack Vectors and the Imperative for Enhanced Security Measures
Abstract
The utilization of PDF files, a ubiquitous format for documents across various industries, has become a prominent tactic in cyberattacks due to their widespread use and intricate structure. This paper examines a malicious PDF file, named "resume.pdf," to uncover the methods and implications of using such files as attack vectors. The file is composed of 20 objects, including five JavaScript references and six streams, emphasizing the complexity and sophistication of the attack. Significantly, the main stream, located in object 19, houses obfuscated JavaScript, a common method for masking malicious operations and evading detection. The attacker's JavaScript is obfuscated using several techniques, including allocating memory for exploit, employing NOP (No-Operation) instructions for buffer overflow, injecting shellcode, and calling Collab.collectEmailInfo, a function specific to the Adobe Reader JavaScript API. The obfuscated code aims to execute shellcode injection, buffer overflow attacks, Adobe Reader exploits, and manipulate memory for potential malware execution. Additionally, Unicode encoding is used to embed the Command & Control (C&C) server address, enabling remote control and exploitation of the compromised system. This intricate combination of techniques demonstrates the lengths to which attackers will go to conceal their malicious intent within seemingly harmless documents.
Cybercriminals often target sectors with frequent document exchanges, such as HR and financial teams, embedding malware in files like resumes or financial statements to infiltrate networks. Picture an HR manager receiving a CV that looks promising but is actually a vehicle for malware. Upon opening it, the organization's system becomes vulnerable to unauthorized access and data compromise. This attack strategy exploits the trust inherent in routine document handling, turning necessary administrative functions into points of vulnerability. The consequences of such an attack can be devastating, ranging from data theft and financial loss to reputational damage and legal repercussions. The ease with which these malicious PDFs can be distributed through email or file-sharing platforms further amplifies the threat they pose to organizations of all sizes.
The detailed technical analysis presented in this paper reveals the presence of a Command & Control (C&C) mechanism, indicating a potential for remote control and exploitation. The breakdown of the document's structure and its key components offers critical insights into the strategies employed by attackers, as well as the potential risks posed by such seemingly innocuous files. By dissecting the various objects and streams within the PDF, the paper provides a comprehensive understanding of how attackers manipulate these elements to achieve their malicious goals. The use of obfuscated JavaScript and Unicode encoding to conceal the C&C server address showcases the sophistication of modern cyber threats and the challenges they present to traditional security measures.
The findings underscore the pressing need for enhanced scrutiny and advanced analytical methods in the detection and mitigation of PDF-based threats. By elucidating the inner workings of this malicious PDF, the paper not only contributes to the understanding of similar threats but also highlights the importance of continual advancements in cybersecurity measures. Traditional antivirus software and basic security protocols are no longer sufficient to protect against the evolving landscape of cyberattacks. Organizations must invest in advanced threat detection systems, machine learning algorithms, and behavioral analysis tools to identify and neutralize these sophisticated threats before they can cause harm.
Organizations must remain vigilant, adopting robust security protocols to detect and neutralize such threats before they compromise sensitive information. This study serves as a vital resource for cybersecurity professionals, emphasizing the importance of regular training and updates in detection capabilities. As attackers continuously evolve their methodologies, the cybersecurity community must similarly adapt, fostering a proactive stance against the ever-changing landscape of cyber threats. This requires a multi-faceted approach, including employee education, incident response planning, and the implementation of defense-in-depth strategies to minimize the attack surface and mitigate the impact of successful breaches.
The insights provided by this examination of "resume.pdf" are essential for improving organizational defenses, helping safeguard against the covert, yet potent, nature of PDF-based cyber attacks. This research advocates for collaborative efforts in the cybersecurity realm to develop comprehensive strategies to protect valuable digital assets and maintain data integrity. By sharing knowledge and best practices, the cybersecurity community can stay one step ahead of attackers and minimize the risk of successful cyberattacks. The fight against PDF-based threats requires a concerted effort from all stakeholders, including software vendors, security researchers, and end-users, to create a safer digital environment for everyone.
Malware to download
Here are the links where you can find the PDF to download. Keep in mind that this is malware, so ensure you download it in a secure environment for your team's task.
Malware Bazzar - https://bazaar.abuse.ch/sample/4dc9b0c20ea61d91d6a1b5bdce76fb5365de0762efb8f6c2925113c6a8950cae/
VirusTotal - https://www.virustotal.com/gui/file/4dc9b0c20ea61d91d6a1b5bdce76fb5365de0762efb8f6c2925113c6a8950cae
Introduction
Portable Document Format (PDF) files stand as a cornerstone of modern digital communication, praised for their portability and consistent appearance across different platforms and devices. However, their complex architecture, designed to accommodate a wide variety of content types, also makes them attractive vehicles for cybercriminals seeking to deliver malicious payloads. This article delves into the anatomy and intent of a malicious PDF, aptly named "resume.pdf," illuminating the dangers hidden within seemingly benign document exchanges.
Organizations, particularly those in administrative roles such as HR and finance, are frequent targets of such attacks due to their routine handling of documents like resumes and invoices. In these departments, receiving a PDF resume is commonplace—a crucial part of assessing potential candidates. Unfortunately, cybercriminals exploit this necessity by embedding malicious scripts within these documents, enabling undetected infiltration of organizational networks. Imagine the scenario: an HR professional receives a PDF that appears to be a promising candidate's CV. As the document is opened, malicious code begins to execute, exposing the system to threats ranging from data theft to remote access by the attacker.
This type of social engineering accentuates the importance of understanding and mitigating the risks associated with PDFs as an attack vector. With 20 embedded objects, including five references to JavaScript and six streams, "resume.pdf" is crafted to bypass traditional security measures. The inherent capabilities of JavaScript within PDFs, intended for legitimate interactions such as form handling and enhanced user experience, are repurposed by attackers to launch and automate cyber attacks.
Notably, the obfuscation of JavaScript within this document presents an added layer of difficulty in identifying the malicious components, hindering straightforward analysis by security professionals. Such techniques are deliberately employed to protect the script's nefarious operations from being easily deciphered. This obfuscation can be designed to exploit vulnerabilities in PDF readers, triggering unauthorized commands when the document is viewed.
The main stream, housed within object 19, signifies a crucial point of interest in this PDF’s structure. Analysis reveals that it contains potentially harmful payloads, exemplifying the need for meticulous dissection of each object and stream within suspicious documents. Additionally, the discovery of a Command & Control (C&C) mechanism within the PDF points to its role in a larger attack framework. The ability to connect the compromised system to an external server for further commands or data extraction amplifies the threat posed by such malicious documents.
In light of these dangers, this analysis aims to enhance awareness and understanding among cybersecurity professionals regarding the manipulation of PDFs for malicious purposes. By dissecting "resume.pdf," the study provides insights into the techniques employed by attackers, guiding the development of more effective detection and prevention strategies.
As the landscape of cyber threats continues to evolve, the vigilance and adaptability of cybersecurity measures are crucial in safeguarding against the exploitation of common digital tools like PDFs. Through comprehensive analysis and knowledge sharing, the community can work towards fortifying defenses, protecting valuable data, and maintaining organizational integrity.
Introduction for PDF File
PDF, or Portable Document Format, is a widely used file format developed by Adobe Systems in 1993. It was designed to present documents consistently across different software, hardware, and operating systems. This versatility makes PDFs invaluable for sharing documents that include text, graphics, and images, all in a device-independent manner with consistent resolution.
A PDF document functions as a collection of objects that describe the appearance and interactive elements of one or more pages. These objects can also encompass additional interactive components and higher-level application data, enhancing the document's functionality beyond static content.
Typically, a PDF document comprises four main components:
- Header : This is a simple one-line entry that identifies the document as a PDF and specifies the version of the PDF format being used.
- Body : This section contains the objects that describe the document's content, which can include text, images, and multimedia elements.
- Cross-reference Table : This table serves as an index, pointing to the location of each object within the file. It plays a critical role in the efficient retrieval and rendering of the document.
- Trailer : The trailer holds information necessary for locating the cross-reference table and provides essential cues to start parsing the PDF.
The physical structure of a PDF file begins with the header, confirming its format. The trailer, found later in the document, references the cross-reference table, which usually starts at a specific byte position, such as 642. The cross-reference table then points to each object within the file, such as byte positions 12 through 518 for objects numbered 1 through 7.
In contrast, the logical structure of a PDF is hierarchical. It begins with a root object identified in the trailer. For instance, in a typical PDF hierarchy, Object 1 might serve as the root, with objects 2 and 3 as its direct children. This hierarchy helps manage and organize the document's content efficiently.
By understanding both the physical and logical structures of PDF files, users and developers can better appreciate their construction, manipulation, and the potential vulnerabilities they may encounter, particularly in scenarios such as malicious document crafting and distribution.
The structure of a PDF document is composed of various elements, which collectively define its format and functionality. Understanding these elements is crucial for analyzing and identifying potential threats within a PDF, such as the one under examination, "resume.pdf."
This particular PDF is constructed with 20 objects, encompassing elements such as metadata, streams, and fonts, each serving a distinct purpose in the document’s presentation and functionality.
- Objects Overview: In a PDF, objects are the fundamental building blocks. Each object can represent various components such as text, images, and embedded scripts. In "resume.pdf," the 20 objects include five JavaScript references and six streams, which are pivotal in understanding the document's malicious intent.
- JavaScript References: JavaScript capabilities in PDFs enable dynamic functionalities. Within "resume.pdf," five references to JavaScript are present. These scripts are typically used for benign tasks like form handling but can also be weaponized to execute malicious code.
- Streams and Filters: Streams are a major element within PDFs, used to encode large amounts of data such as images or executed scripts. "resume.pdf" contains six streams, with the main one located at object 19. This stream likely houses the obfuscated JavaScript code, a common technique used by attackers to hide harmful intent. PDF streams can be compressed using various encoding filters like FlateDecode, which can make analysis more challenging.
- Object 19: The main stream in object 19 is central to the PDF's function, containing potentially malicious payloads. The obfuscation within this stream indicates an attempt to conceal the underlying operations from straightforward detection and analysis. This stream exemplifies the complexity of modern PDF-based attacks.
- Catalog and Cross-Reference Table: The catalog object serves as the root of the PDF, orchestrating the structure of other objects. The cross-reference table is likewise crucial, providing offsets for every object, ensuring that the PDF reader can efficiently access each part of the document.
- Encryption and Security Features: While analysis of "resume.pdf" does not indicate direct encryption, some malicious PDFs employ encryption to protect and conceal their payloads. Understanding potential security features is vital to fully decrypt and uncover hidden threats.
By dissecting these elements, this analysis seeks to unravel the intricacies of "resume.pdf," providing a window into the strategies employed by malicious actors and the technical hurdles they create for cybersecurity professionals.
Object identification
To conduct a thorough technical analysis of the "resume.pdf" file, I utilized the PDFid tool, which is fundamental in examining PDFs for hidden threats. PDFid is a lightweight utility designed to detect potentially malicious content embedded within PDF files by identifying various key elements and patterns known to be associated with such threats.
The first step in the analysis involved running the PDFid tool to obtain an overview of the PDF's structure. The tool provided valuable insights into the PDF by identifying the number and types of objects present, specifically focusing on:
- Obj (Object): PDFid revealed the presence of numerous objects within the document, which are integral components containing the content and instructions that define the PDF’s appearance and behavior.
- Stream: The tool highlighted the streams in the document, which are binary sections often used to compress and store complex data like images, or in this case, potentially obfuscated malicious scripts.
PDFiD is a tool designed to scan PDF documents for specific strings, counting their occurrences—both in plain and obfuscated forms. This functionality is crucial for identifying potentially harmful PDFs that may contain elements such as JavaScript or those set to execute an action upon opening. The tool effectively handles name obfuscation, aiding in the detection of hidden threats.
The primary purpose of PDFiD is to act as an initial triage step in the analysis of PDF documents. By quickly highlighting PDFs that contain suspicious elements, it helps analysts prioritize which documents require further scrutiny. Once a document is flagged as suspicious by PDFiD, a more in-depth analysis can be conducted using a tool like pdf-parser. Pdf-parser provides detailed insights into the document's structure and content, offering comprehensive information essential for uncovering complex threats. This systematic approach ensures a thorough investigation of PDFs, starting with a broad scan and narrowing down to a detailed analysis.
It's very interesting within this tool is that we can see the use of "/ (slash)" to show information that is located within the objects of a PDF:
Following the initial scan with PDFid, a deeper analysis was conducted on specific elements detected within the PDF:
- /Page: This element was examined to understand the layout and the number of pages, as attackers sometimes use hidden or unexpected pages to execute malicious content.
- /Encrypt: This parameter was checked to determine if the PDF was encrypted. Encryption could be used to protect sensitive content in legitimate uses or to obscure malicious scripts in an attack scenario.
- /ObjStm (Object Stream): Object streams are used to compress multiple objects together. Their presence was scrutinized since they can be abused to hide the presence of malicious code, complicating straightforward analysis.
- /JS and /JavaScript: These elements were flagged as high-risk, as they could contain scripts used to execute unauthorized actions when the PDF is opened. Obfuscated JavaScript is particularly concerning, as it’s often employed to conceal the true intentions of the code. Every instance of /JS and /JavaScript was carefully dissected.
- /AA or /OpenAction: This directive was analyzed for any scripts or actions set to execute automatically upon opening the PDF. Such automatic actions can be used to trigger embedded JavaScript without user interaction.
- /AcroForm: Analyzed for interactive form elements that might include scripts or actions embedded within forms. AcroForms can serve legitimate purposes but also provide avenues for executing malicious code.
It's evident that the PDF contains five instances of JavaScript. This finding is certainly concerning, as the presence of multiple scripts within a single PDF file can indicate the potential for suspicious or malicious activity, don't you think?
Another interesting aspect is the presence of an OpenAction within the PDF. This indicates that an automatic action is triggered when the document or page is viewed. In my experience, malicious PDF documents containing JavaScript often include such automatic actions to launch the script without requiring any user interaction.
Technical Analysis
The body of a PDF file is composed of various objects that make up the document's content. These objects can include image data, fonts, annotations, and text streams, among others. Security features can be implemented to enhance the document's protection, enabling restrictions on unauthorized printing, viewing, editing, or modifying. Invisible objects or elements, such as animations or interactive graphics, can also be incorporated to enrich the document's functionality. Additionally, PDFs support two types of numbers: integers and real numbers. Users can also integrate a logical structure to organize the content effectively.
To analyze the fundamental elements within a PDF, I used a tool called PDF-PARSER, developed by Didier Stevens. Unlike PDF viewers, PDF-parser does not render documents but instead dissects them to identify their core components. Despite being a "quick-and-dirty" script, it provides valuable information about the document's structure. The tool can apply filters, such as FlateDecode for zlib decompression, to process streams and extract their contents.
The first command I executed was pdf-parser -a, which displays statistical data about the PDF document, offering a snapshot of its structure.
One of my favored options is the --raw switch, which outputs raw data rather than the printable Python representation. This is especially useful when examining indirect objects by their IDs, which are version-independent. If multiple objects share the same ID (regardless of version), they are all displayed.
The reference option allows selection of all objects that reference a specified indirect object, also version-independent. The type option lets you select all objects of a particular type. Because type is a Name, it is case-sensitive and must begin with a slash character (/).
Through the use of PDF-parser, I was able to delve deeper into the PDF's structure, gaining insights that are critical in identifying potential security risks embedded within the document.
In the process of deeply examining a suspicious PDF file, I utilized PDF-parser, a tool crafted to dissect PDF documents and reveal their underlying structure. Using the command:
pdf-parser –raw or pdf-parser -w
I was able to extract all raw data outputs, avoiding the more traditional, printable representations often seen in PDF analysis. This approach allows for a more granular look at the document's internals, providing a clearer view of the objects and their interactions within the file. Obj 1 emerged as a significant focus of the analysis. This object contains a stream, an important component often used to encode detailed data like images or scripts. The stream in Obj 1 had two references to other objects: Obj 2 and Obj 3 . Within Obj 3 , a stream is associated with an image.
It's not uncommon for PDFs to embed media this way, but in the context of suspicious activity, such streams warrant further scrutiny. Additionally, an intriguing detail was uncovered: a reference to an XObject within one of these associated objects, suggesting the possibility of embedded graphical content or complex data.
What is Stream
A stream page in PDF terms is essentially a section of the PDF that contains objects encoded and compressed to house resources like text, images, or, sometimes, scripts that execute upon viewing. The significance of stream pages lies in their ability to host hidden or obfuscated content, making them a common target for malicious payloads.
Further in the document, Obj 7 became noteworthy due to its multiple references. This object is connected to objects ranging from Obj 8 to Obj 13 . One particular object in this chain possesses an OpenAction coupled with a JavaScript segment, which automatically activates upon the document's opening. The presence of JavaScript in a PDF context is often a red flag, as it can be used to execute potentially harmful actions without user intervention. This discovery prompted a deeper investigation into these objects to fully understand their role and the risks they pose.
I then focused on Obj 14 , which serves as a connection to yet another object, Obj 17 . The latter contains a stream; however, what's peculiar about this stream is its length—it is surprisingly short. This observation could indicate a placeholder or a reference to a more significant piece of the puzzle elsewhere in the document.
By returning to the Obj 7, hypothesized to be the root object of the document, I uncovered additional links. Obj 9 is a pivotal piece in this network, referencing Obj 16 , which in turn points to Obj 18.
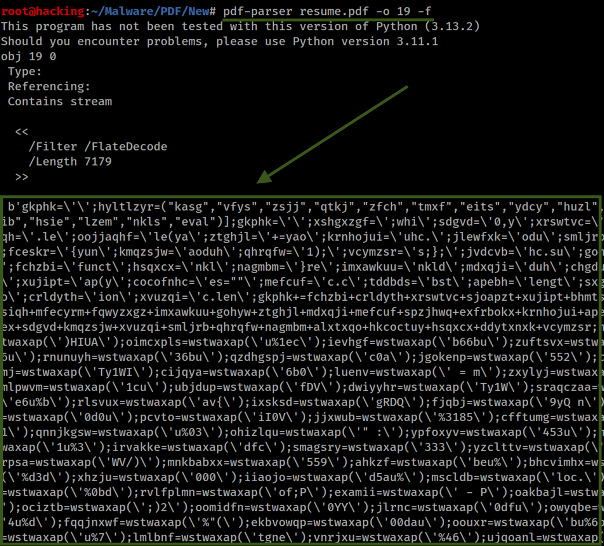
Finally, Obj 18 links to Obj 19 , leading us to our primary object of interest. Obj 19 contains a considerably large stream, with a length of 7179. This size is notably large compared to other objects in the document, suggesting it hosts a substantial amount of data, potentially aligning with our suspicions of concealed malicious content.
Finally, a look at the trailer confirms that Obj 7 is indeed the root object of this PDF. This verification is crucial as it solidifies our understanding of the document's hierarchy and the role each object plays.
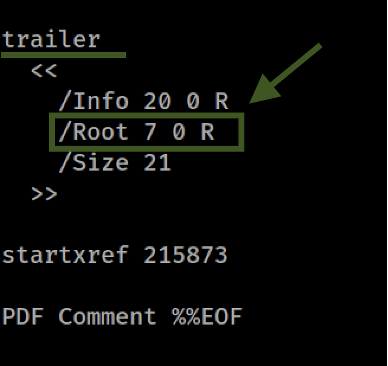
Now we have a line to follow within our analysis, as we face the challenge of unveiling the information encapsulated within the Stream. An object stream is a specialized stream object capable of containing other objects, which can be employed to obfuscate data, adding another layer of complexity to our task. Our focus is on Obj 19 , where the presence of the FlateDecode filter signals that the data is compressed and potentially harbors concealed content.
In the context of PDF analysis, FlateDecode is a compression method using the zlib format, fostering efficient data storage by minimizing file size. This compression, while beneficial for legitimate purposes, poses a hurdle when attempting to manually inspect the content, as it necessitates decompression to access the original data format. Such obfuscation is often leveraged to hide malicious payloads within the PDF, demanding adept techniques to extract and analyze the data safely.
We can use two tools in our arsenal: pdf-parser and pdftk.
The pdf-parser tool, renowned for dissecting PDF documents, enables us to delve into the file's structural intricacies by parsing objects and streams with precision. This tool provides the facility to explore deeply embedded scripts, metadata, and inter-object relationships by applying and handling filters like FlateDecode to transform and reveal compressed data.
pdf-parser resume.pdf –o 13 –f
- pdf-arser: Tool
- resume.pdf: file
- -o : Object
- -f : pass stream object through filters (FlateDecode, ASCIIHexDecode, ASCII85Decode, LZWDecode and RunLengthDecode only)
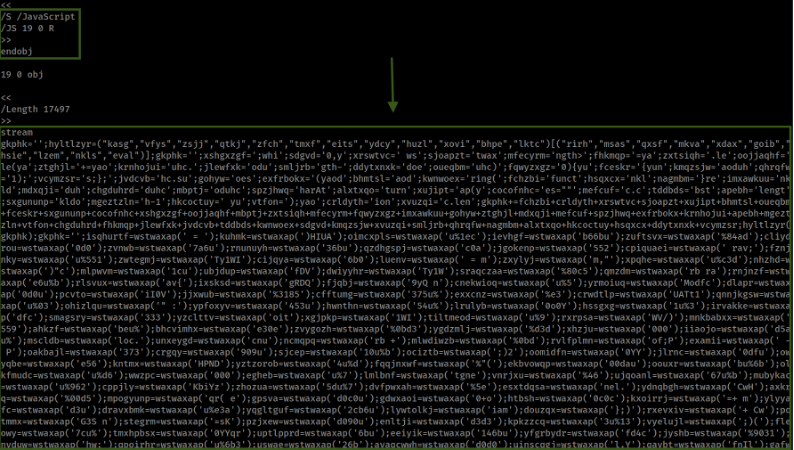
Another tool to follow our analysis is pdftk, the PDF Toolkit, proves invaluable for its robust capabilities in handling and modifying PDF files. This open-source tool excels at operations such as splitting, merging, and decompressing PDFs, which are essential for our current objective. By using pdftk, we can deftly decompress streams within Obj 19 , stripping away the compression layer applied by FlateDecode and laying bare the hidden data within the stream. A handy tool for manipulating PDF, and the feature that we'll use is uncompress Page Streams, basically we can run this command.
pdftk resume.pdf output dump.txt uncompress

Upon examining the contents of the stream, we discovered that it contains code obfuscated in JavaScript. To make this code visible and understandable, we must employ various deobfuscation techniques. These techniques will allow us to unravel the obfuscation, revealing the code's actual functionality and intent.
To help you begin separating and understanding this obfuscated JavaScript code, I can provide some guidance on how you might start deconstructing it. However, please keep in mind that handling and analyzing such code should always be done with caution and within a controlled and legal environment.
Here's a general approach you could follow:
- Identify Function Calls : Look for any calls to functions like eval or similar, which are often used to execute the decoded version of obfuscated strings.
- Break Down String Concatenations : You'll notice that there are many assignments and concatenations like gkphk += ... These are combined to eventually form executable JavaScript code. By separating each string and understanding how they are concatenated, you'll reveal the script's structure:
a.Identify all instances of assignments to gkphk and other critical variables.
b.Track how each piece is appended or used. This often constructs a larger command that is executed later.
- Replace Variables with Values : Substitute variables like fchzbi, crldyth, and so forth with the strings they represent, if they're not dynamically generated. This will help you make sense of the actual logic.
- Use Automated Tools : Use a JavaScript beautifier or deobfuscator to aid in restructuring the code. Tools like JSBeautifier or online JavaScript deobfuscators might give you a clearer presentation of the code.
- Manual Inspection : Scan the now-readable script for known malicious functions and their parameters.
Creating a Python script to deobfuscate an obfuscated JavaScript code like the one you shared involves breaking down the process into manageable steps. Here's a simple way to begin tackling this task. This script will focus on reconstructing and interpreting the obfuscated script in a more readable form.
- Step 1: Extract and Map Variables
- First, extract all variable assignments to understand their actual content. This step is crucial because most of the script's logic builds upon these variables.
- Step 2: Concatenate Strings
- After understanding what each variable represents, you should concatenate them to form executable or readable code blocks.
- Step 3: Decode/Execute
- Finally, for functions or operations executed in the obfuscated script, mimic that execution in Python to obtain the final deobfuscated code.
First Part: Decoding
To decode the provided obfuscated JavaScript code, we'll need to break it down into parts and understand the deobfuscation steps. We'll use Python to simulate and decode both parts of the obfuscated code.

Explanation
-
Variable Initialization:
gkphk='';initializes an empty string variablegkphk.
-
Obfuscated Function Assignment:
hyltlzyr=("kasg","vfys","zsjj","qtkj","zfch","tmxf","eits","ydcy","huzl","xovi","bhpe","lktc")[("rirh","msas","qxsf","mkva","xdax","goib","hsie","lzem","nkls","eval")];is an obfuscated way to assign a function tohyltlzyr. The code uses two arrays where the second array acts as an index into the first array. The second array's last element is "eval", which is used to select the 10th element (index 9) from the first array. Therefore,hyltlzyris assigned the valueeval.
Explanation:
-
Variable Initialization:
gkphk='';initializes an empty string variablegkphk.
-
Obfuscated Function Assignment:
hyltlzyr=("kasg","vfys","zsjj","qtkj","zfch","tmxf","eits","ydcy","huzl","xovi","bhpe","lktc")[("rirh","msas","qxsf","mkva","xdax","goib","hsie","lzem","nkls","eval")];is an obfuscated way to assign a function tohyltlzyr. The code uses two arrays where the second array acts as an index into the first array. The second array's last element is "eval", which is used to select the 10th element (index 9) from the first array. Therefore,hyltlzyris assigned the valueeval.
-
String Assignments:
- The code then assigns various short strings to other variables, such as: - The code then assigns various short strings to other variables, such as:
xshgxzgf = ';whi';
sdgvd = '0,y';
xrswtvc = ' ws';
sjoapzt = 'twax';
mfecyrm = 'ngth>';
fhkmqp = '=ya';
zxtsiqh = '.le';
oojjaqhf = 'le(ya';
ztghjl = '+=yao';
krnhojui = 'uhc.';
jlewfxk = 'odu';
smljrb = 'gth-';
ddytxnxk = 'doe';
oueqbm = 'uhc)';
fqwyzxgz = '0){yu';
fceskr = '{yun';
kmqzsjw = 'aoduh';
qhrqfw = '1);';
vcymzsr = 's;};';
jvdcvb = 'hc.su';
gohyw = 'oes';
exfrbokx = '(yaod';
bhmtsl = 'aod';
kwnwoex = 'ring(';
fchzbi = 'funct';
hsqxcx = 'nkl';
nagmbm = '}re';
imxawkuu = 'nkld';
mdxqji = 'duh';
chgduhrd = 'duhc';
mbptj = 'oduhc';
spzjhwq = 'harAt';
alxtxqo = 'turn';
xujipt = 'ap(y';
cocofnhc = 'es=""';
mefcuf = 'c.c';
tddbds = 'bst';
apebh = 'lengt';
sxgununp = 'kldo';
mgeztzln = 'h-1';
hkcoctuy = ' yu';
vtfon = ');yao';
crldyth = 'ion';
- 4. String Concatenation:
gkphk+=fchzbi+crldyth+xrswtvc+sjoapzt+xujipt+bhmtsl+oueqbm+fceskr+sxgununp+cocofnhc+xshgxzgf+oojjaqhf+mbptj+zxtsiqh+mfecyrm+fqwyzxgz+imxawkuu+gohyw+ztghjl+mdxqji+mefcuf+spzjhwq+exfrbokx+krnhojui+apebh+mgeztzln+vtfon+chgduhrd+fhkmqp+jlewfxk+jvdcvb+tddbds+kwnwoex+sdgvd+kmqzsjw+xvuzqi+smljrb+qhrqfw+nagmbm+alxtxqo+hkcoctuy+hsqxcx+ddytxnxk+vcymzsr;concatenates a series of the previously defined variables intogkphk.
Based on the let’s create some basic Python script to decode this first part:
import re
def decode_js(js_code):
variables = {}
var_pattern = r'(\w+)=[\'"](.*?)[\'"]'
for match in re.finditer(var_pattern, js_code):
var_name, value = match.groups()
variables[var_name] = value
gkphk_pattern = r'gkphk\+=(.+)'
gkphk_match = re.search(gkphk_pattern, js_code)
if gkphk_match:
gkphk_value = gkphk_match.group(1)
gkphk_components = re.findall(r'(\w+)', gkphk_value)
gkphk_result = ''.join(variables.get(comp, '') for comp in gkphk_components)
variables['gkphk'] = gkphk_result
hyltlzyr_pattern = r'hyltlzyr=(\w+,\w+,\w+,\w+,\w+,\w+,\w+,\w+,\w+,\w+)\[(\w+,\w+,\w+,\w+,\w+,\w+,\w+,\w+,\w+,\w+)\]'
hyltlzyr_match = re.search(hyltlzyr_pattern, js_code)
if hyltlzyr_match:
hyltlzyr_value = hyltlzyr_match.group(1)
hyltlzyr_index = hyltlzyr_match.group(2)
variables['hyltlzyr'] = 'eval' # The index 'eval' is used to set hyltlzyr to 'eval'
return variables
# JavaScript code to decode
js_code = """
**PAST THE COMPLETE CODE HERE**
"""
# Decode the code
decoded_variables = decode_js(js_code)
# Write the results to a text file
with open('first_code_results.txt', 'w') as file:
for key, value in decoded_variables.items():
file.write(f"{key} = \"{value}\"\n")Let's start with the first part, and then proceed to the second part.

The result received from executing the first part of the code appears to be a JavaScript function named wstwaxap. This function takes a string yaoduhc as an argument and reverses it. Let's break down the function and explain its functionality:
function wstwaxap(yaoduhc) {
yunkldoes = "";
while (yaoduhc.length > 0) {
yunkldoes += yaoduhc.charAt(yaoduhc.length - 1);
yaoduhc = yaoduhc.substring(0, yaoduhc.length - 1);
}
return yunkldoes;
}
Explanation of the wstwaxap Function:
-
Function Definition:
- The function
wstwaxapis defined to take a single parameteryaoduhc.
- The function
-
Initialization:
- An empty string
yunkldoesis initialized to store the reversed string.
- An empty string
-
Reversing the String:
- The function uses a
whileloop to iterate as long asyaoduhchas characters. - Inside the loop:
yaoduhc.charAt(yaoduhc.length - 1)retrieves the last character ofyaoduhc.- This character is appended to
yunkldoes. yaoduhc = yaoduhc.substring(0, yaoduhc.length - 1)removes the last character fromyaoduhc.
- The function uses a
-
Return Statement:
- The function returns the reversed string stored in
yunkldoes.
- The function returns the reversed string stored in
Example Usage:
If you pass a string to wstwaxap, it will reverse that string. For example:
Javascript
let result = wstwaxap("hello");
console.log(result); // Output: "olleh"
The Python script that you've been using to decode the JavaScript code correctly identified and reconstructed this function. If you want to verify this functionality in Python, you can write an equivalent function:
yunkldoes = ""
while len(yaoduhc) > 0:
yunkldoes += yaoduhc[-1]
yaoduhc = yaoduhc[:-1]
return yunkldoes
# Example usage
result = wstwaxap("hello")
print(result) # Output: "olleh"
based on that, I need to focus on the second part of the code, where probably we can find the right information about the wstwaxap variable.
Second Part: Decoding
The second part of the code continues to build on gkphk and executes it using hyltlzyr, which is eval. The second part also defines additional variables using the wstwaxap function, which reverses strings.

Here's how we can decode this in Python:
def decode_js(js_code):
variables = {}
wstwaxap_pattern = r'(\w+)=wstwaxap\((.+?)\)'
wstwaxap_matches = re.finditer(wstwaxap_pattern, js_code)
for match in wstwaxap_matches:
var_name = match.group(1)
encoded_str = match.group(2)
# Simulate reversing the string as per the 'wstwaxap' function
decoded_str = encoded_str[::-1]
variables[var_name] = decoded_str
gkphk_pattern = r'gkphk\+=(.+)'
gkphk_match = re.search(gkphk_pattern, js_code)
if gkphk_match:
gkphk_value = gkphk_match.group(1)
gkphk_components = re.findall(r'(\w+)', gkphk_value)
gkphk_result = ''.join(variables.get(comp, '') for comp in gkphk_components)
variables['gkphk'] = gkphk_result
return variables
# JavaScript code to decode
js_code = """
PASTE THE COMPLETE JAVASCRIPT CODE HERE
"""
# Decode the code
decoded_variables = decode_js(js_code)
# Write the results to a text file
with open('decoded_results.txt', 'w') as file:
for key, value in decoded_variables.items():
file.write(f"{key} = \"{value}\"\n")
Once executed this code, we have the results:
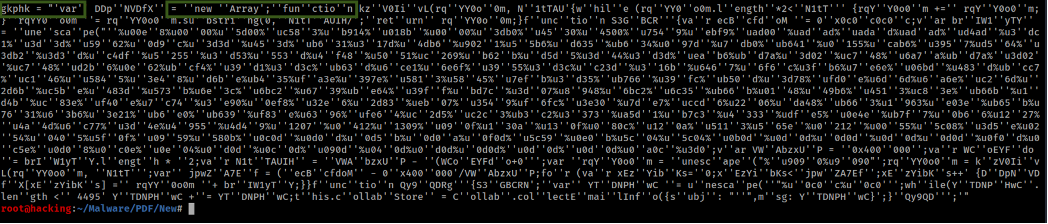
We can see the Variable “var” and a “New Array” probably with some instruction, let’s inprove our previous script and create another Python script to clean this code and put in on single line to be interpreted.
Explanation of the New Decoded JavaScript Code
Understanding the wstwaxap Function
We previously discovered that the function wstwaxap is used to reverse strings. Meaning that every assignment in this form:
isqhurtf = wstwaxap(' = ')
Means that isqhurtf will be assigned the reversed string:
isqhurtf = "' = '"
Thus, our script needs to reverse all instances of wstwaxap("...") and store their results.
Key Parts of the JavaScript Code
- Variable Assignments with
wstwaxap()- The script assigns obfuscated variables using reversed strings.
- Our goal is to reverse each string to recover its true value.
- Obfuscated Function
- The decoded script contains a function called
wstwaxapwhich reverses strings. - This function is used to obfuscate multiple variable assignments.
- The decoded script contains a function called
- Decoding
gkphkgkphkis built by concatenating different variable values into a single function.
- Malicious Intent?
- The final decoded JavaScript script seems to manipulate memory and execute potential exploits by dynamically building and executing a payload.
- This method of encoding/decrypting at runtime is often found in obfuscated malware
import re
def decode_js(js_code):
variables = {}
# Extract and reverse wstwaxap assignments
wstwaxap_pattern = r'(\w+)=wstwaxap\([\'"](.*?)[\'"]\)'
for match in re.finditer(wstwaxap_pattern, js_code):
var_name = match.group(1)
encoded_str = match.group(2)
decoded_str = encoded_str[::-1] # Reverse string to decode
variables[var_name] = decoded_str
# Extract and concatenate gkphk components
gkphk_pattern = r'gkphk\+=(.+)'
gkphk_match = re.search(gkphk_pattern, js_code)
if gkphk_match:
gkphk_value = gkphk_match.group(1)
gkphk_components = re.findall(r'(\w+)', gkphk_value)
gkphk_result = ''.join(variables.get(comp, '') for comp in gkphk_components)
variables['gkphk'] = gkphk_result
return variables
# Paste the complete JavaScript code here
js_code = """
PASTE YOUR COMPLETE JAVASCRIPT CODE HERE
"""
# Decode the JavaScript code
decoded_variables = decode_js(js_code)
# Write the results to decoded_results.txt
with open(' decoded_results.txt', 'w') as file:
for key, value in decoded_variables.items():
file.write(f"{key} = \"{value}\"\n")
print("Decoding complete. Results saved to decoded_results.txt.")
How the Python Script Works
- Finds
wstwaxap()assignments:
- Uses
re.finditer()to find all occurrences ofvar_name = wstwaxap("..."). - Extracts and reverses the string inside
wstwaxap(). - Saves the decoded result into a dictionary.
- Reconstructs
gkphkby joining its components:
- Finds which variables contribute to
gkphk. - Replaces each variable reference with its actual decoded value.
- The final decoded
gkphkforms an executable JavaScript function.
- Writes results to a file:
- Saves each decoded variable as
variable = "value" in decoded_results.txt.
After executed the Python script, he have the full results

Let’s go more deeply in this code, the JavaScript snippet provided is an obfuscated code that performs memory manipulation and potentially prepares an exploit by decoding and constructing shellcode in memory. Let's break it down carefully.
1. S3GBCRNU Function
This function sets up memory and builds an executable payload.
Step-by-Step Breakdown

- Defines a function
S3GBCRNUwhich is used later inQy9QDRgu.
(A) Creating ecBcfdoM Buffer Variable

- Initializes a memory buffer variable
ecBcfdoMwith0x0c0c0c0c. This represents a series of non-executable memory.
(B) Defining brIW1yTY Shellcode in Unicode Escape Sequence
- Uses
unescapeto decode a long hexadecimal sequence. %u####%u####format represents Unicode encoding.- This gets converted into binary shellcode which may later be executed.
(C) Allocating Memory for Exploit

0x400000represents 4MB of memory space.

- Calculates the length of
brIW1yTYin bytes.

- Ensures enough space is reserved for the shellcode to avoid overwriting other memory.
(D) Crafting the Final Payload

%u9090%u9090translates to NOP sled, used in buffer overflow exploits.0x90is the NOP (No-Operation) instruction, making execution slide until it reaches shellcode.

- Calls an unknown function
kzV0IivL, probably inflating the shellcode. - Computes memory offset values.

for (var xEzYibKs=0; xEzYibKs<jpwZA7Ef; xEzYibKs++) {
DDpNVDfX[xEzYibKs] = rqYY0o0m + brIW1yTY;
}
- Iterates through and fills memory
DDpNVDfXwith the NOP sled (rqYY0o0m) followed by shellcode (brIW1yTY).
2. Qy9QDRgu Function
This function triggers the attack and executes the exploit payload.
(A) Calls S3GBCRNU

- Ensures the shellcode preparation is complete.
(B) Creating Large Memory Balloon

- Fills memory with
0x0C0Cas placeholder data. - Expands the memory allocation to ensure data structure corruption.
(C) Launching an Exploit

- Calls Collab.collectEmailInfo, which only exists in Adobe Reader JavaScript API.
- This hints that the script is targeting a PDF vulnerability.
Doing some researches on the internet we can find many information about this vulnerability Collab.collectEmailInfo is a JavaScript API method found in Adobe Acrobat and Adobe Reader. It is part of the Collaborate (Collab) JavaScript object, which Adobe designed for document collaboration and data collection in PDFs.
This method has been exploited in past security vulnerabilities to execute JavaScript malware inside PDFs.
Common Exploit Techniques:
- Heap Spray Attack
- Uses shellcode to overwrite memory and execute arbitrary code.
- Steal Data
- Extracts email addresses & system info without consent.
- Embed Malware in PDFs – As we can see in our PDF.
- Malicious PDFs trick users into executing JavaScript exploits inside Adobe Reader.
Suspicious code example – Created by private AI.
var exploit_code = unescape("%u9090%u9090..."); // NOP sled → buffer overflow
Collab.collectEmailInfo({subj: "Security Update", msg: exploit_code});
Important Note
Collab.collectEmailInfo can be a useful feature for legitimate collaboration, but it's often exploited in malware attacks inside PDFs.
3. Execution and Exploit Trigger

- Calls
Qy9QDRgu, which sets everything into motion.
Just to summarize the code:
- Shellcode Injection
- Buffer Overflow Attack
- Adobe Reader Exploit Attempt
- Targeting Memory Manipulation for Potential Malware Execution
Unicode
Based on our experience, the provided sequence is obfuscated shellcode stored in Unicode escape sequences. This type of encoding is used in JavaScript-based buffer overflows, typically seen in browser exploits, PDF exploits, or JavaScript malware.
Each part of the sequence follows the pattern %uXXXX, which represents two bytes of hexadecimal code interpreted as a word (16-bit instruction) by the CPU.
Unicode is a universal character encoding standard that assigns a unique code point to every character, symbol, or emoji used in the world's writing systems. It ensures that computers globally process, store, and display text correctly, regardless of language or platform.
We need to convert this Unicode code in machine code, usually in a binary file, that you can use some tool to analyze such as: IDA Pro, Ghidra, objdump, Malzilla among others
Let’s work in Python script to decode this Unicode code and convert to binary file.
import re
def unicode_to_bin(shellcode, output_file="decoded_shellcode.bin"):
# Extract %uXXXX formatted hex values
hex_values = re.findall(r'%u([0-9A-Fa-f]{4})', shellcode)
if not hex_values:
print("Error: No valid Unicode shellcode found!")
return
try:
# Convert from Unicode escape to raw bytes
decoded_bytes = bytes.fromhex(''.join(hex_values))
# Write binary output
with open(output_file, "wb") as f:
f.write(decoded_bytes)
print(f"Decoded shellcode saved as {output_file}")
except ValueError as e:
print(f"Error: Invalid hexadecimal characters detected. Check your input! {e}")
return
# Paste your Unicode shellcode inside the triple quotes
shellcode = """
PASTE YOUR UNICODE SHELLCODE HERE
"""
# Convert and save
unicode_to_bin(shellcode)
The binary was created as you can see below – decoded_shellcode.bin
Another way to find this information is using a tool called Mallzila for Windows platform,
Malzilla is a malware analysis tool designed for reverse-engineering malicious web pages and scripts—especially those used in drive-by downloads, phishing, and browser exploits. It is commonly used by security researchers to analyze obfuscated JavaScript, malicious iframes, suspicious URLs, and hidden exploits.
The program provides full visibility into webpage source code and HTTP headers, making it an essential resource for security researchers. Additionally, MalZilla offers built-in decoders to help deobfuscate JavaScript, aiding in the detection of hidden threats.
To extract meaningful information in MalZilla, it is often necessary to convert UCS-2 encoded text into readable form. But what exactly is UCS-2?
UCS-2 is a character encoding standard where each character is represented by a fixed length of 16 bits (2 bytes). It serves as a fallback option on numerous GSM networks when messages cannot be encoded using GSM-7 or when a language needs more than 128 characters to be displayed. The Universal Coded Character Set (UCS) is defined by the international standard ISO/IEC 10646, known as Information technology — Universal Coded Character Set (UCS), along with its amendments. This standard forms the foundation for various character encodings. The most recent version of UCS includes over 136,000 abstract characters, each with a unique name and an integer identifier known as its code point. The ISO/IEC 10646 standard is jointly maintained with The Unicode Standard ("Unicode"), ensuring that both are identical in terms of code.
Using the Malzilla we can generate a binary with this information that are contained and encoded within this code. Now we just need some tool to help us finally reach C&C using the attacker.
One useful tool is XORSearch, developed by Didier Stevens, which is designed to locate a specified string within a binary file that has been encoded using XOR, ROL, ROT, or SHIFT methods. In an XOR encoded binary file, some or all of the bytes are XORed with a constant value known as the key. A file encoded with ROL (or its counterpart ROR) has its bytes rotated by a specific number of bits, which is also referred to as the key. In a ROT encoded file, the alphabetic characters (A-Z and a-z) are shifted by a certain number of positions. A SHIFT encoded file involves shifting the bytes left by a designated number of bits (the key): this process shifts all bits of the first byte to the left, with the most significant bit (MSB) of the second byte becoming the least significant bit (LSB) of the first byte, and so on for subsequent bytes. Malware developers often use XOR and ROL/ROR encoding to obscure strings such as URLs. Therefore, XORSearch enables us to detect such strings within encoded files.

Done, we have now identified the command and control (C&C) server that was used to collect all the victim IPs - specifically, 94.247.2.157. Attempting to access this site today will fail as the server is no longer operational. It's likely that the attacker utilized the TOR network to execute this attack, and this IP address in Netherlands, Europe, was probably the final exit point they used.
Conclusion
In conclusion, the meticulous examination of the malicious PDF file "resume.pdf" has unveiled the sophisticated tactics cybercriminals employ to exploit the widespread use of PDF files in their attacks. The file's complex structure, consisting of 20 objects, including five JavaScript references and six streams, showcases the intricate planning and technical expertise behind these attacks. The primary stream, embedded in object 19, contains obfuscated JavaScript that utilizes a variety of techniques, such as memory allocation for exploits, NOP instructions for buffer overflows, shellcode injection, and the invocation of Adobe Reader-specific functions like Collab.collectEmailInfo. These methods, coupled with the use of Unicode encoding to conceal a Command & Control mechanism, illustrate the lengths to which attackers will go to compromise organizational security while evading detection. The deliberate targeting of sectors with frequent document exchanges, such as human resources and finance, further emphasizes the need for heightened vigilance and advanced detection capabilities to mitigate the risks posed by these seemingly innocuous files.
The findings of this study underscore the critical importance of adopting robust security protocols and investing in cutting-edge threat detection technologies to stay ahead of the evolving cyber threat landscape. Organizations must prioritize employee education, incident response planning, and the implementation of defense-in-depth strategies to minimize the impact of successful breaches. Traditional antivirus software and basic security measures are no longer sufficient to protect against the sophisticated nature of modern cyberattacks. As attackers continue to refine their techniques, the cybersecurity community must maintain a proactive stance, collaborating to develop comprehensive strategies that safeguard valuable digital assets and maintain data integrity. By sharing knowledge and best practices, the cybersecurity community can work together to create a safer digital environment for everyone.
Moving forward, further research is needed to explore the development of advanced machine learning algorithms capable of detecting obfuscated code and identifying novel attack vectors within PDF files. Investigating the potential for real-time analysis and automated response systems could significantly enhance an organization's ability to neutralize threats before they cause harm. Additionally, examining the effectiveness of user behavior analytics in identifying suspicious interactions with PDF files could provide valuable insights into early detection and prevention strategies. Researchers should also focus on developing more robust methods for identifying and decoding Unicode-encoded C&C server addresses, as this technique is becoming increasingly common in PDF-based attacks. Furthermore, exploring the intersection of PDF-based attacks with other attack vectors, such as phishing emails or social engineering tactics, could provide a more holistic understanding of how attackers exploit multiple channels to achieve their goals. By pursuing these research avenues, the cybersecurity community can continue to strengthen its defenses against the ever-evolving landscape of PDF-based cyberattacks, ultimately creating a more secure digital ecosystem for organizations and individuals alike.
The presence of a Command & Control mechanism within the file indicates a high level of organization and threat potential, highlighting the interconnected nature of modern cyber threats. The deliberate obfuscation of JavaScript within "resume.pdf" reveals a targeted attempt to evade detection mechanisms, emphasizing the necessity for more advanced analytical tools capable of deobfuscating scripts to identify their true function. Cybersecurity solutions must continue to evolve alongside these tactics, incorporating machine learning and behavioral analysis to better predict and counteract potential threats. Command & Control servers play a crucial role in orchestrating attacks, serving as hubs for remote command execution and data extraction. Identifying and neutralizing these channels is essential for mitigating an attack's impact. The detection of such a mechanism within "resume.pdf" signifies the document's potential as part of a larger attack campaign, necessitating vigilance across digital communications.
As PDFs remain a common document format, attackers will continue to exploit their features to deliver malicious content. Detailed file analysis should be a cornerstone of organizational cybersecurity strategies. Security teams must be trained to recognize the subtle indicators of embedded threats, ensuring that malicious PDFs are intercepted before reaching end-users. The continuous advancement of security software and protocols is vital to countering the sophistication of PDF-based attacks. Collaborative efforts across the cybersecurity community, including information sharing and the development of comprehensive tools for file analysis, can significantly enhance defenses.
In practice, the study of "resume.pdf" illustrates the broader landscape of cyber threats, where innovation and adaptability in security practices are key to safeguarding digital assets. Embracing a comprehensive defense strategy that includes both technology and human expertise will be vital in the ongoing battle against cyber threats. By fostering a culture of continuous learning and collaboration, organizations can better protect themselves against the ever-evolving tactics of cybercriminals, ensuring the integrity and security of their digital assets in an increasingly complex threat landscape.
References
· https://www.techrxiv.org/users/894249/articles/1271253-dissecting-pdf-malicious
· https://labs.senhasegura.blog/malware-hunting-dissecting-pdf-file/
· https://filipipires.com/posts/Malware-Analysis/
· https://blog.didierstevens.com/programs/pdf-tools/
· https://github.com/filipi86/MalwareAnalysis-in-PDF
· https://blog.didierstevens.com/2008/04/08/quickpost-back-from-black-hat-europe-2008/
· https://www.cvedetails.com/cve/CVE-2007-5659/
· https://nvd.nist.gov/vuln/detail/cve-2007-5659
· https://cve.mitre.org/cgi-bin/cvename.cgi?name=cve-2007-5659
· https://hackertarget.com/geoip-ip-location-lookup/